
DeepSeek V2 marks a significant breakthrough in AI efficiency. The system achieves a 42.5% reduction in training costs compared to its previous version. This new model boasts 236 billion total parameters while activating only 21 billion for each token. Such parameter efficiency comes with an impressive context length support of 128,000 tokens.
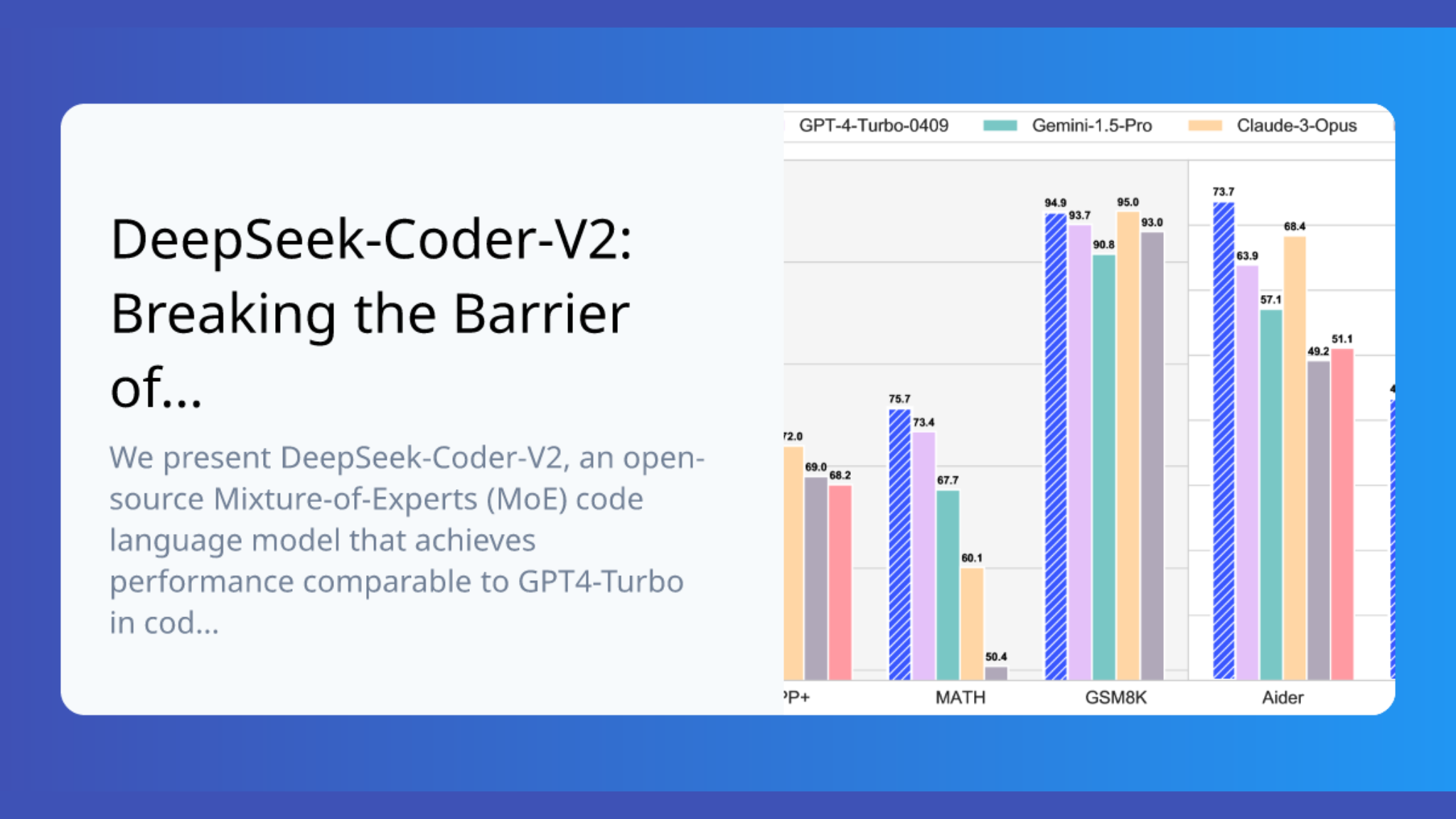
The model’s innovative architecture has drastically cut down Key-Value cache needs by 93.3%. This achievement stands out even more given its training on 8.1 trillion tokens. DeepSeek V2’s coding variant, DeepSeek-Coder-V2, now supports 338 programming languages and performs on par with GPT-4-Turbo in code-related tasks.
This piece delves into DeepSeek V2’s path to these efficiency gains while delivering top performance across key standards. We’ll learn about its architecture, optimization methods, and ground applications that make it a transformative force in large language models.
Understanding DeepSeek V2’s Architecture

DeepSeek V2’s architecture brings together new approaches that deliver amazing efficiency. The model works with 236 billion parameters but uses just 21 billion parameters per token. It can handle an impressive 128K token context length.
Overview of MoE Architecture
DeepSeek V2’s Mixture-of-Experts (MoE) architecture takes a smart approach to parameter management. The model splits its Feed-Forward Networks (FFNs) into specialized parts that activate only the parameters needed for specific tasks. This design choice helps use resources better during training and when the model runs.
Exploring the Multi-head Latent Attention Mechanism in DeepSeek V2
Multi-head Latent Attention (MLA) represents a big step forward from traditional attention methods. MLA uses low-rank key-value joint compression to cut down Key-Value cache needs when running. This approach works better than regular Multi-Head Attention (MHA) while using much less memory.
DeepSeekMoE Framework Implementation
DeepSeekMoE brings two key innovations to the table:
- Expert segmentation at a fine level that helps specialists learn better
- Expert isolation that shares resources and cuts down on duplicate knowledge between routed experts
The framework also keeps MoE-related communication costs in check with device-limited routing. This architecture works much better than regular MoE setups and delivers similar results with far fewer computational needs.
These architectural elements work together to help DeepSeek V2 deliver exceptional results. The combination of MLA and DeepSeekMoE leads to a 93.3% reduction in KV cache requirements and makes generation 5.76 times faster.
Breakthrough Cost Optimization Techniques with DeepSeek V2
DeepSeek V2’s design puts cost savings first. The model cuts training costs by 42.5% instead of using expensive hardware solutions.
Sparse Computation Strategies
DeepSeek V2’s sparse computation works by activating only specific parameters. Each token connects to a maximum of three devices to make the best use of resources. The model balances workload without extra computing overhead and keeps routing efficient.
Memory Usage Optimization
Smart memory management makes DeepSeek V2 highly efficient. Multi-head Latent Attention shrinks Key-Value cache size by 93.3%, which lets the model handle longer sequences better. The compression works through:
- Low-rank joint compression of keys and values
- Absorption technique for query and output vectors
- Separate computation of RoPE and non-RoPE attention scores
These improvements boost speed dramatically. The model runs 20.4 times faster for single requests and 3.63 times faster for batched requests on NVIDIA A100 GPUs.
DeepSeek V2: Training Infrastructure Improvements
The training setup uses advanced parallel processing and hardware tweaks. DeepSeek V2 spreads different layers across devices through pipeline parallelism. The model evenly distributes routed experts across eight devices. Training took 2,788 thousand H800 GPU hours, which proves it’s more cost-effective than traditional methods.
FP8 training makes things even more efficient with precise quantization and better accumulation accuracy. This keeps the model accurate while using less memory, which leads to faster training cycles without losing performance.
Performance Benchmarks and Analysis Powered by DeepSeek V2
Standard results show DeepSeek V2’s exceptional abilities in many domains. The model ranks at the top among open-source models using just 21B activated parameters.
Comparison with Previous Models
DeepSeek V2 performs better than DeepSeek 67B in almost all standards. We see its superior results in English, code, and math evaluations. The model achieves top scores on the MMLU standard with minimal activated parameters.
Task-Specific Performance Metrics for DeepSeek V2
The chat version of DeepSeek V2 shows remarkable skills in a variety of tasks:
- AlpacaEval 2.0: 38.9 length-controlled win rate
- MTBench: 8.97 overall score
- AlignBench: 7.91 overall score
DeepSeek V2 matches GPT4-Turbo’s capabilities in coding tasks. The model handles code snippets up to 128K tokens and supports 338 programming languages.
Resource Utilization Statistics
DeepSeek V2’s efficient architecture leads to unprecedented resource optimization. The model needs 172.8K GPU hours per trillion tokens on an H800 cluster, while DeepSeek 67B requires 300.6K GPU hours. A single node with 8 H800 GPUs helps DeepSeek V2 produce more than 50K tokens per second.
The model’s pricing structure reflects these improvements. Input tokens cost USD 0.14 and output tokens USD 0.28 per million tokens. These rates make DeepSeek V2 more cost-effective than industry averages.
DeepSeek V2: Real-World Applications and Impact
DeepSeek V2’s real-world applications show how it can transform AI adoption in various industries. This Chinese AI startup’s affordable foundation models have removed a major hurdle to enterprise deployment.
Enterprise Implementation Cases
Companies of all types now use DeepSeek V2 in their daily operations. Healthcare providers use the model to detect diseases early and identify infections quickly. Banks and financial firms detect fraud and analyze transaction patterns with this technology. E-commerce platforms use DeepSeek to create personalized shopping suggestions and manage their inventory more effectively.
Cost-Benefit Analysis
The model offers excellent value through its pricing structure:
- Input tokens at USD 0.14 per million tokens
- Output tokens at USD 0.28 per million tokens
- Training costs of USD 5.58 million on 2,048 Nvidia H800 chips
DeepSeek’s profit margin stays above 70%. Small businesses and individual developers can now access advanced AI features without spending too much money.
Environmental Sustainability Impact
DeepSeek V2’s efficiency has a positive effect on the environment. The model cuts down data center power usage, which makes up 4.4% of all U.S. electricity consumption. Its streamlined computing approach could help limit the expected doubling or tripling of data center energy use by 2028.
The environmental advantages go beyond just saving energy. Companies can now run routine AI tasks on phones instead of data centers, thanks to DeepSeek V2’s innovative training methods. This improved efficiency might change how regulators approve power infrastructure for AI operations. The model proves that AI development can progress without harming the environment.
Conclusion
DeepSeek V2 is a breakthrough in AI efficiency that proves superior performance doesn’t just need massive computational resources. The model uses an innovative Mixture-of-Experts architecture and Multi-head Latent Attention mechanism. This design helps it achieve unmatched parameter efficiency and supports a massive 128,000-token context length.
The numbers tell an impressive story. Training costs dropped by 42.5%, while Key-Value cache requirements shrank by 93.3%. The model now supports 338 programming languages. These improvements make advanced AI available to businesses of all sizes and help more organizations access cutting-edge language models.
Healthcare, finance, and e-commerce sectors already show DeepSeek V2’s practical value. The model’s computing approach tackles environmental issues by cutting data center energy use without compromising performance.
DeepSeek V2 marks a major advance in eco-friendly AI development. It shows that better efficiency and performance can go hand in hand and sets new benchmarks for resource-smart AI development. This perfect mix of capability and efficiency points to an exciting future where computational power enables rather than limits innovation


